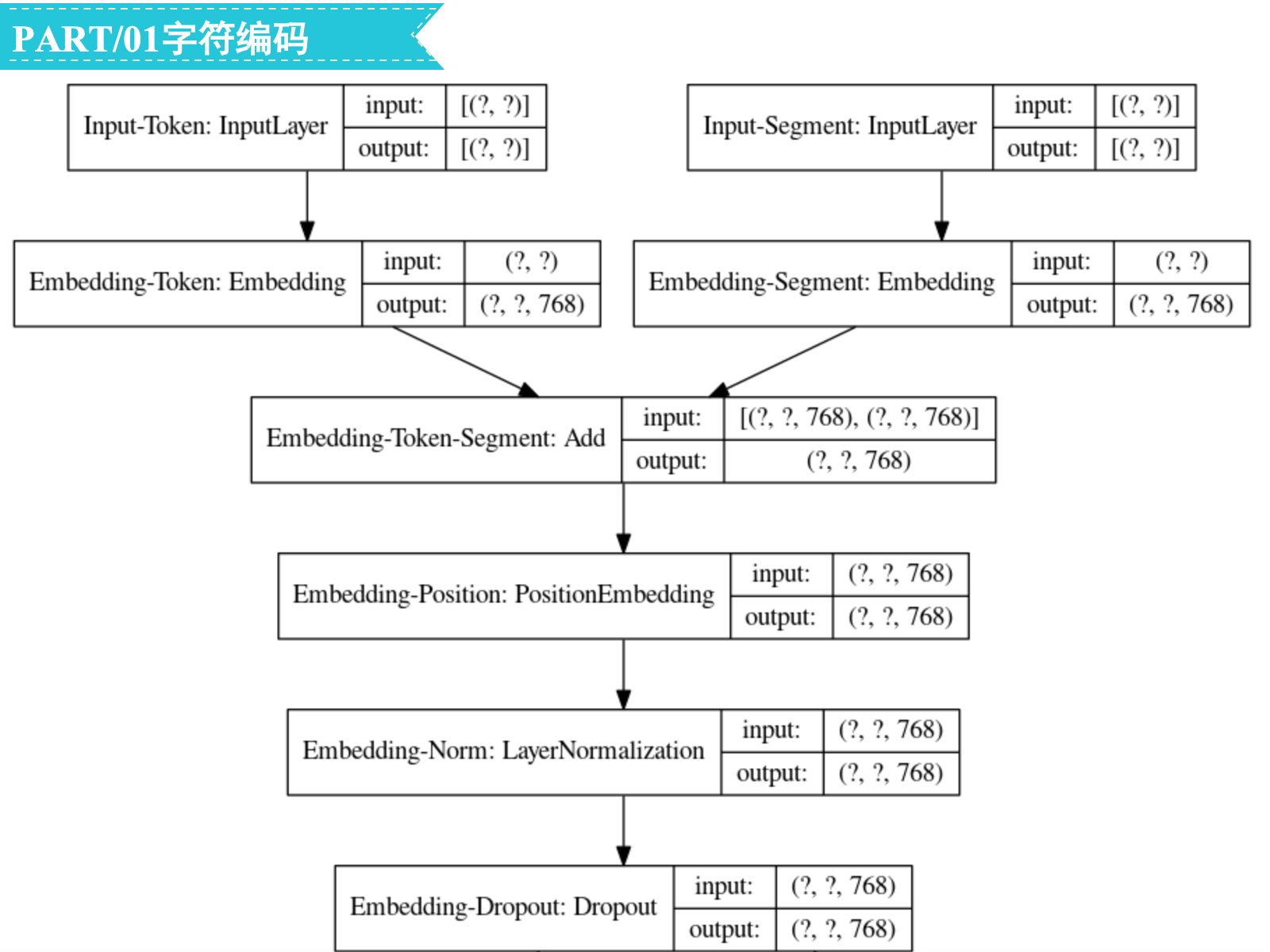
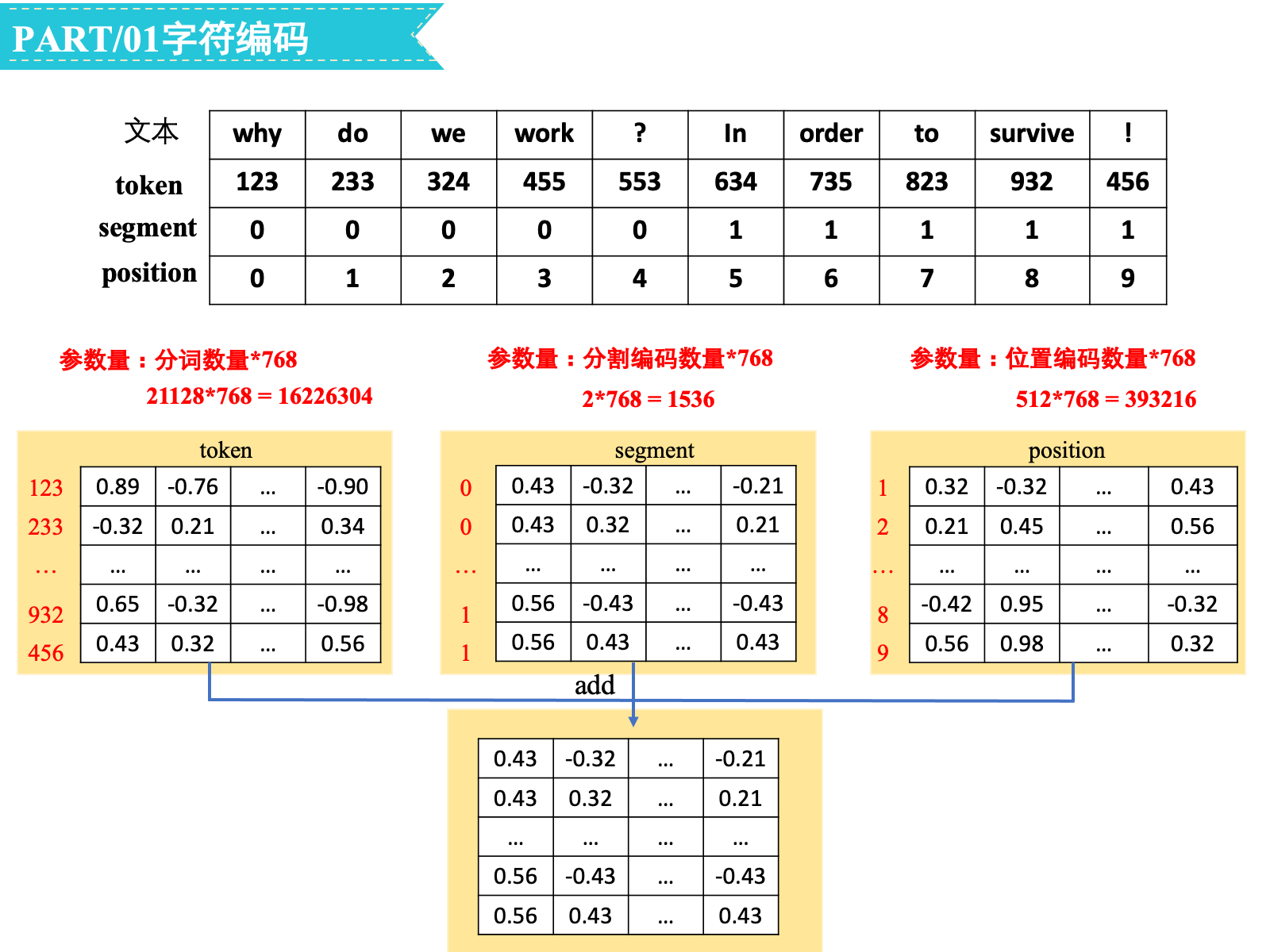
考虑三种不同的embedding:
-
Token:tokenizer中一共涉及21128个字/词(vocab_size=21128),参数量为21128∗768=16226304
-
Segment:一共有两种segment(type_vocab_size=2),参数量为2∗768=1536
-
Position:序列最长为512(max_position_embeddings=512),参数量为512∗768=393216
三种embedding相加之后还要再做一次layer normalization,每个normalization用到两个参数(均值和方差),768维的向量做normalization需要的参数量为2∗768=1536
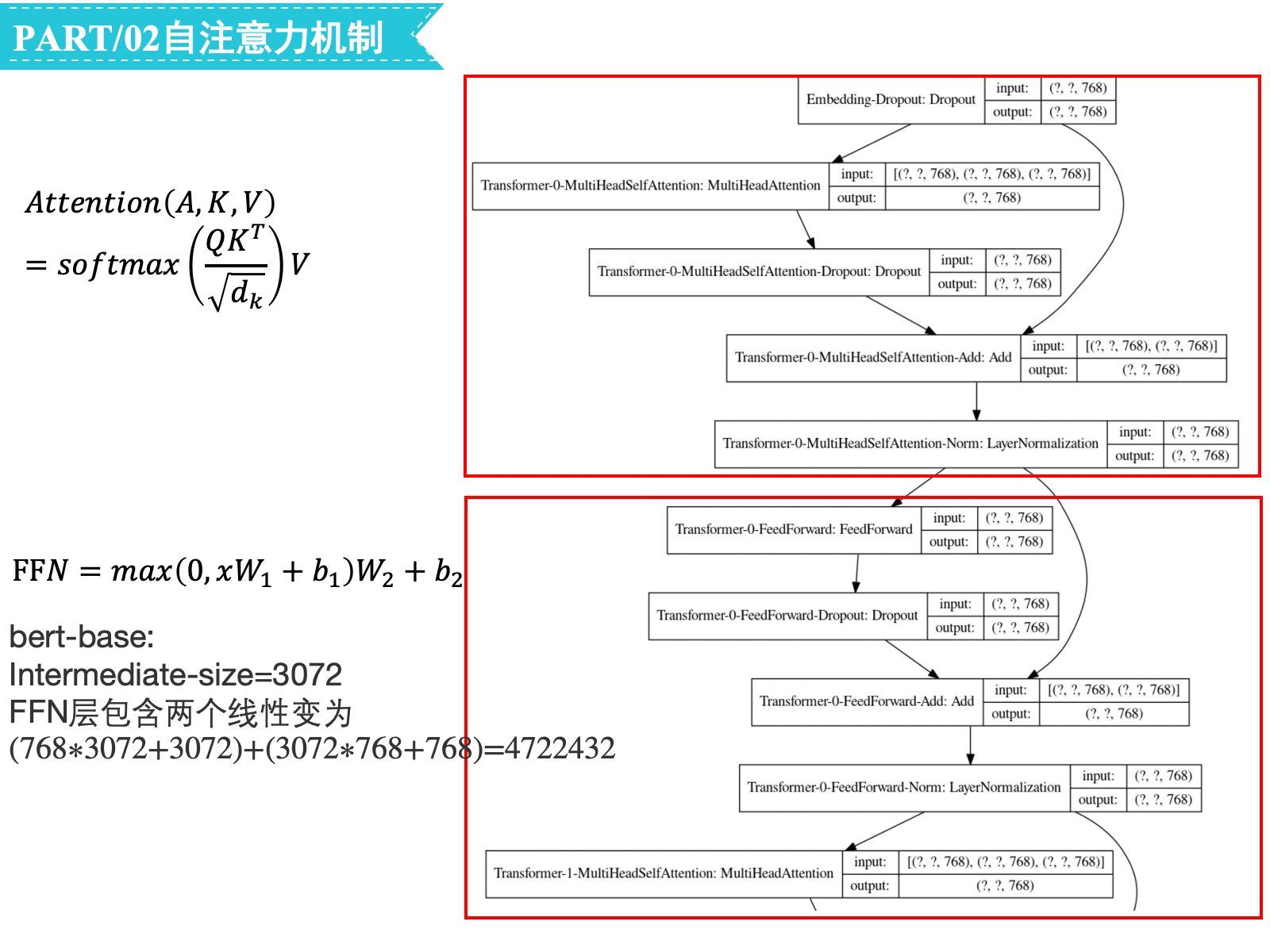
self-attention sublayer
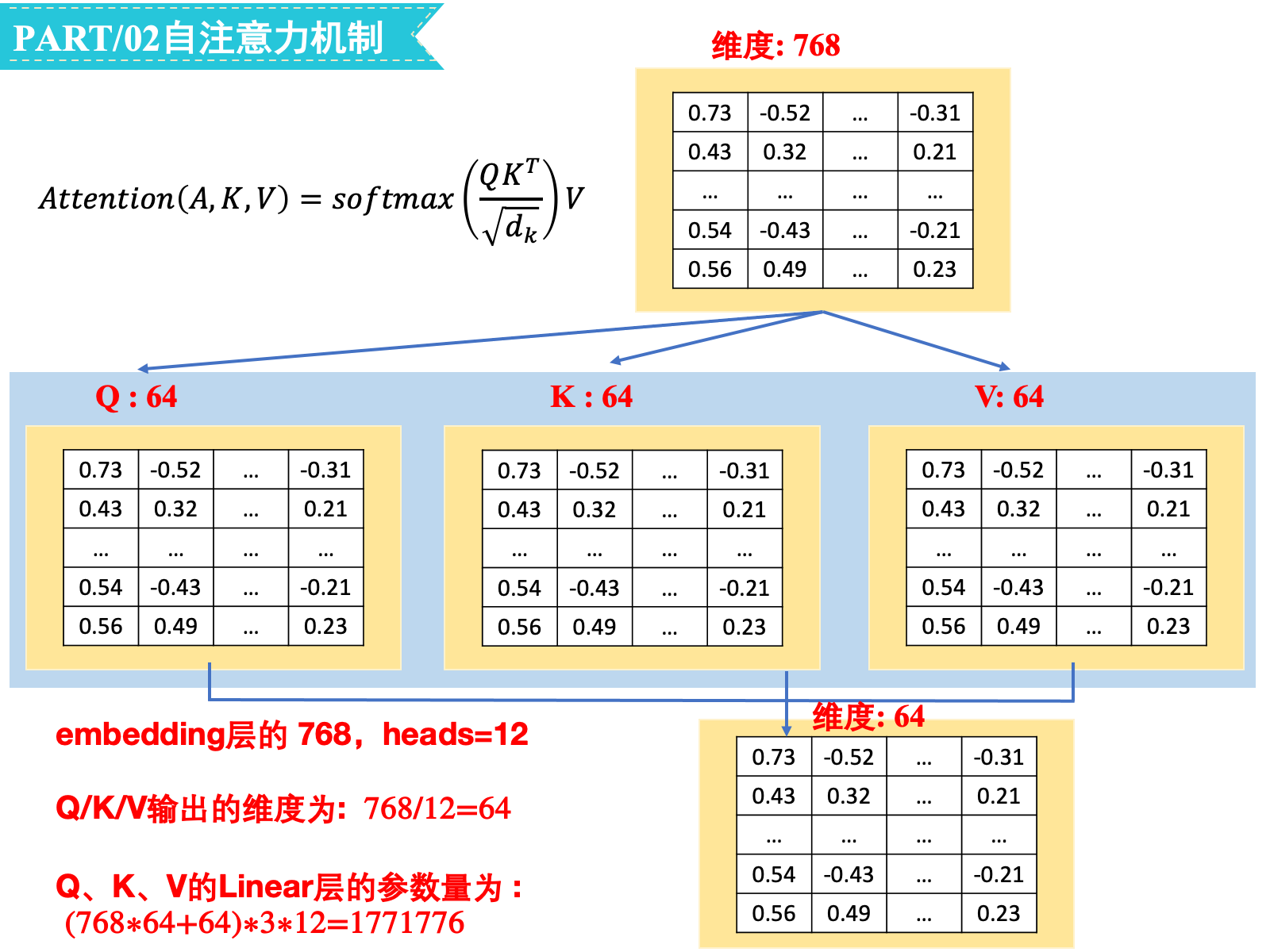
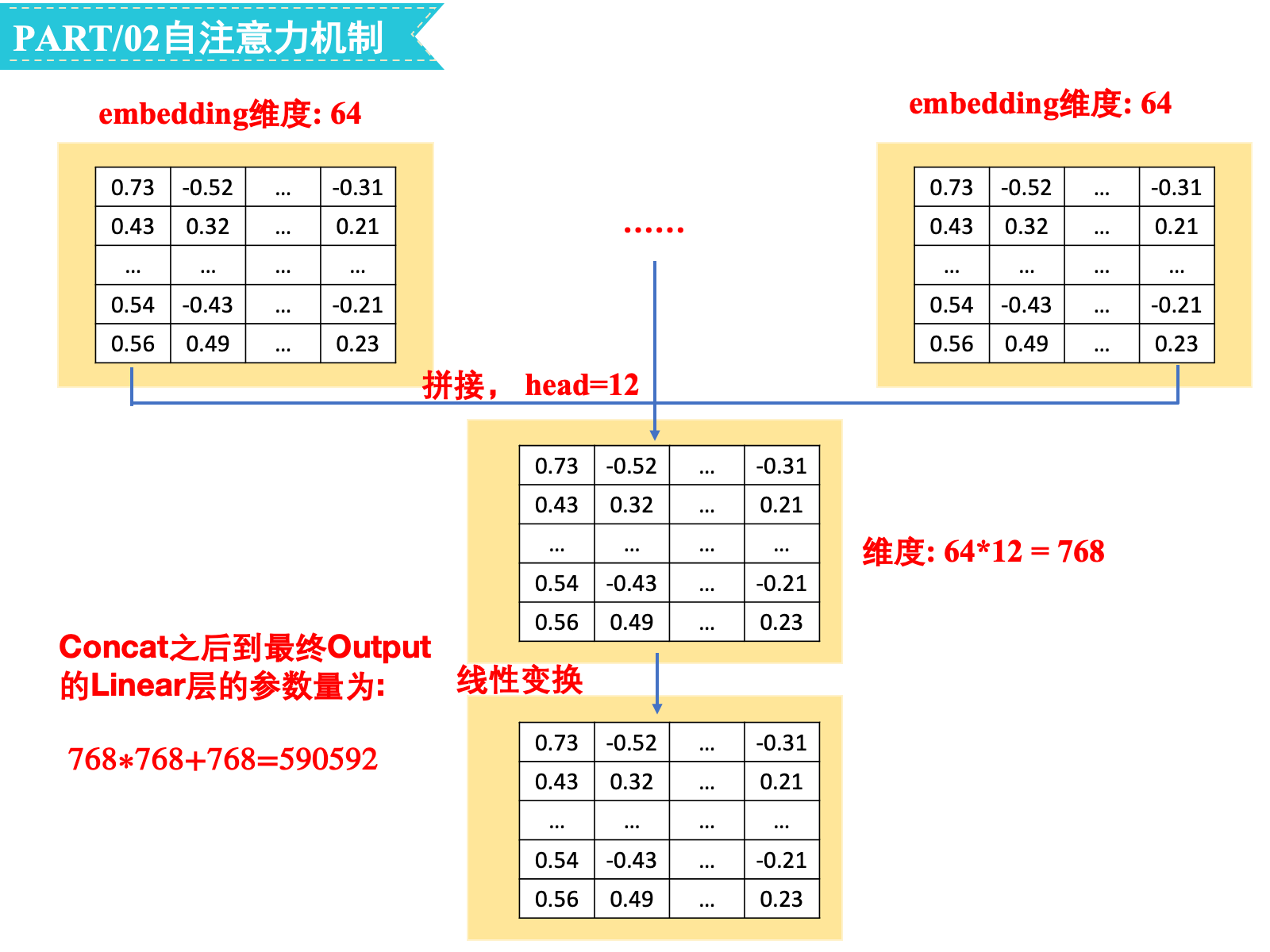
embedding层的hidden_size=768,num_attention_heads=12,Q/K/V输出的维度为768/12=64:
-
Q、K、V的Linear层的参数量为(768∗64+64)∗3∗12=1771776
-
Concat之后到最终Output的Linear层的参数量为64∗12∗768+768=590592
-
合计参数量为1771776+590592=2362368
feed-forward sublayer
对FFN,bert-base的intermediate_size=3072,FFN层包含两个线性变换,对应的参数为(768∗3072+3072)+(3072∗768+768)=4722432
layer-normalization
self-attention sublayer和feed-forward sublayer都用到了layer normalization,对应的参数量都是2∗768=1536