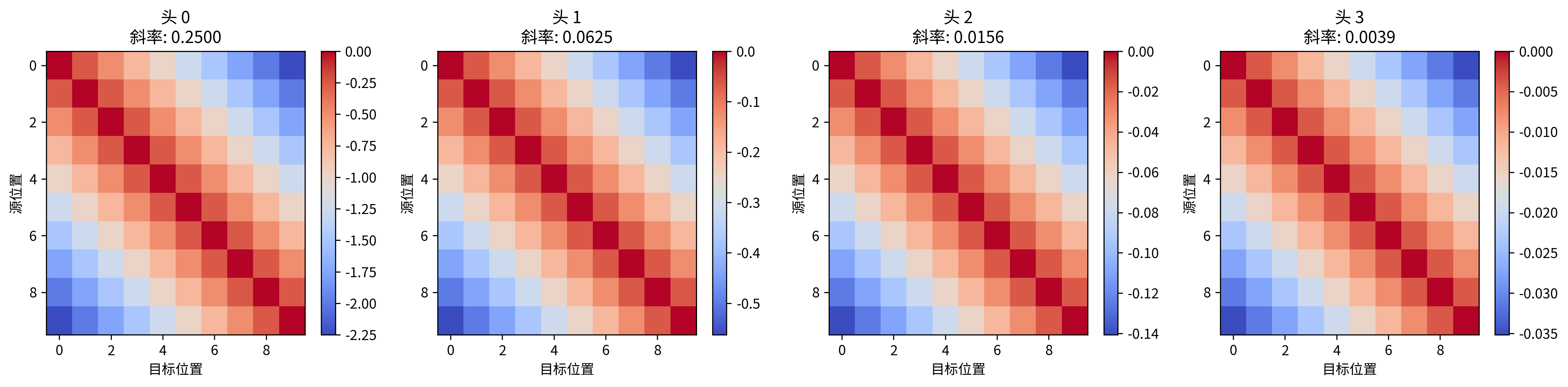
1. 背景:为什么需要位置编码?
原始的 Transformer 模型本身是 置换不变 的。也就是说,它对输入序列中单词的顺序不敏感。如果不提供位置信息,模型会将句子 “猫追老鼠” 和 “老鼠...
分类目录归档:算法手撕
原始的 Transformer 模型本身是 置换不变 的。也就是说,它对输入序列中单词的顺序不敏感。如果不提供位置信息,模型会将句子 “猫追老鼠” 和 “老鼠...
计算顺序优化:从 (Q·K^T)·V 改为 Q·(K^T·V),避免显式计算注意力矩阵
复杂度降低:从 O(n²d) 降到 O(nd²),当序列长度 n > 特征维度 d 时...
from torch import nn
import torch.nn.functional as F
import torch
import math
class MoELayer(nn....import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers import GPT2L...# softmax
import torch
# X = torch.tensor([-0.3, 0.2, 0.5, 0.7, 0.1, 0.8])
# X_exp_sum = X.exp(...from torch import nn
import torch.nn.functional as F
import torch
import math
class SelfAttenti...import torch
from einops import rearrange
NEG_INF = -1e10 # -infinity
EPSILON = 1e-10
Q_LEN = ...import torch
from torch import nn
import numpy as np
class ScaledDotProductAttention(nn.Module)...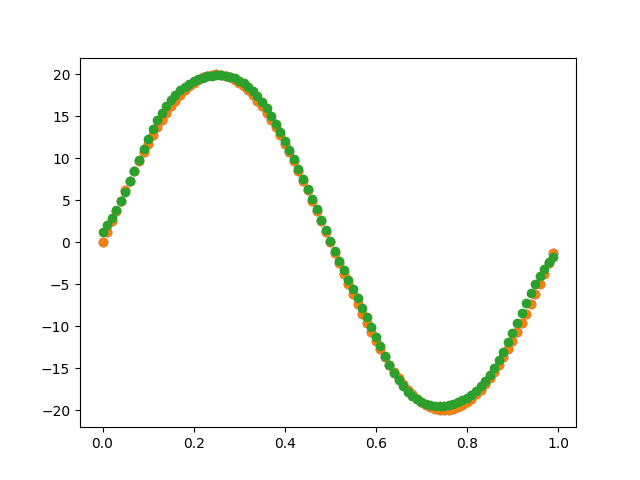
import numpy as np
from matplotlib import pyplot as plt
# 生成权重以及偏执项layers_dim代表每层的神经元个数,
# 比如[...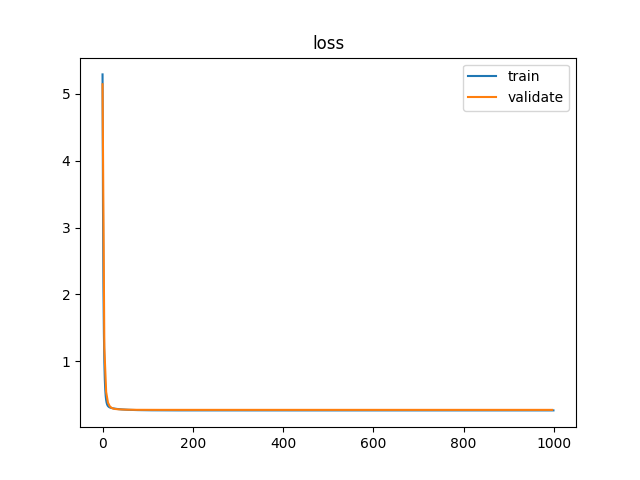
# 数据加载
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import...