简介
之前的模型(seq2sql,sqlnet)完全忽略了各个column的数据类型,但数据类型其实是一个很重要的信息,比如在预测WHERE子句时,只有数值类型的column才可以比较大小,字符串类型的值则不行。基于以上想法,TypeSQL充分利用了question中每个单词的类型信息(比如某个单词为列名、整数值等),并取得了新的SOTA。
结构
SQLNet为模版中的每一种成分(共6种)设定了单独的模型,而TypeSQL对此进行了改进,对于相似的成分,例如SELECT_COL 和COND_COL以及#COND(条件数),这些信息间有依赖关系,通过合并为单一模型,可以更好建模。TypeSQL使用3个独立模型来预测模版填充值:
- MODEL_COL:SELECT_COL,#COND,COND_COL
- MODEL_AGG:AGG
- MODEL_OPVAL:OP, COND_VAL
技巧
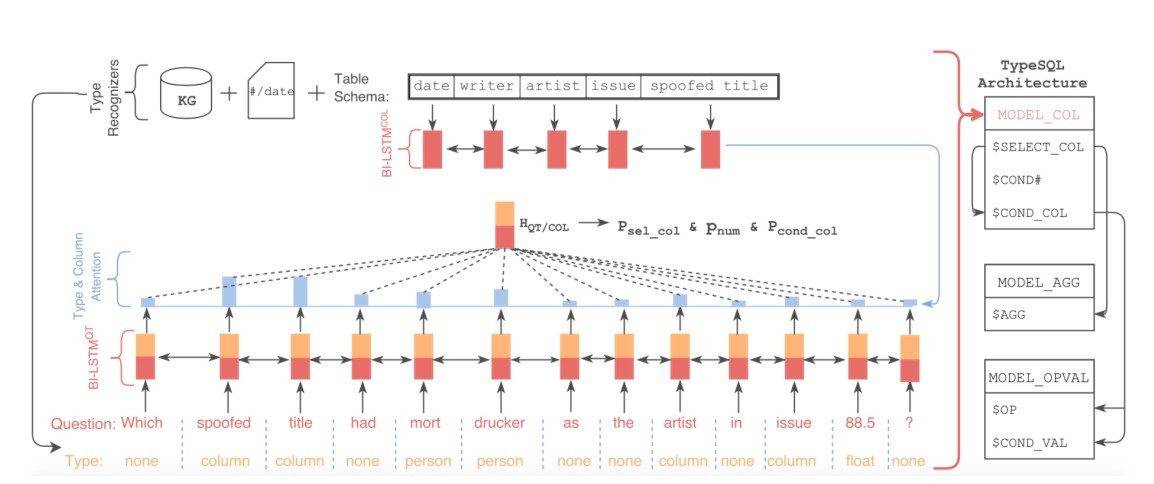
与SQL Net一样采用slot filling的思想,填充sketch的各个slot,并大幅度精简用到的BiLSTM(12->6)。 为了更好地建模文本中出现的罕见实体和数字,TypeSQL显式地赋予每个单词类型。 其类型识别过程如下:将问句分割n-gram (n取2到6),并搜索数据库表、列。对于匹配成功的部分赋值column类型赋予数字、日期四种类型:INTEGER、FLOAT、DATE、YEAR。对于命名实体,通过搜索FREEBASE,确定5种类型:PERSON,PLACE,COUNTREY,ORGANIZATION,SPORT。这五种类型包括了大部分实体类型。当可以访问数据库内容时,进一步将匹配到的实体标记为具体列名(而不只是column类型)。
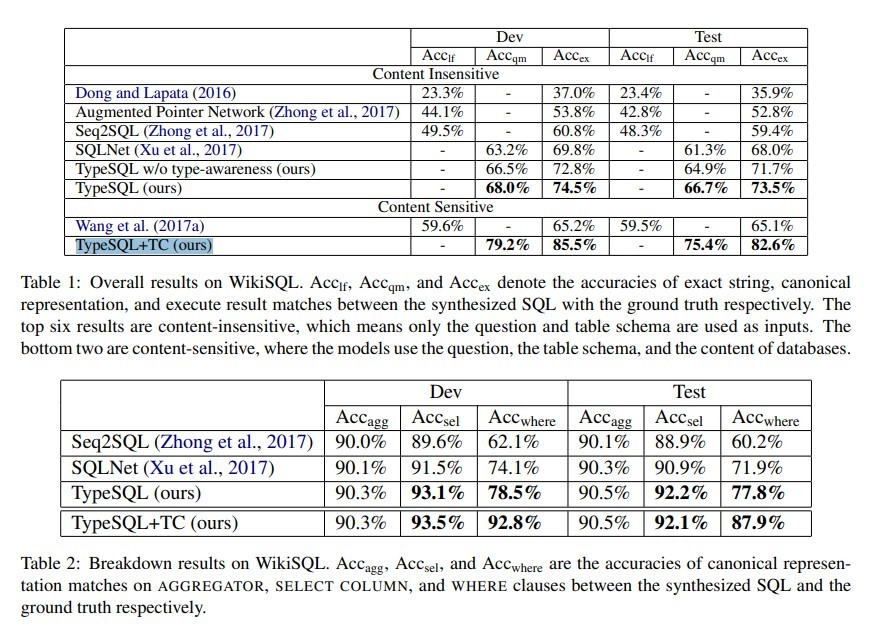
结果