简介
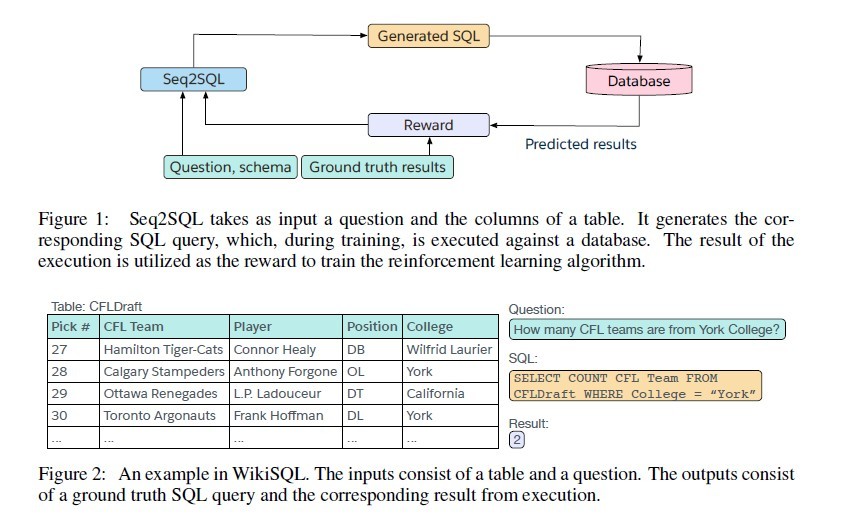
- 提出一个深层神经网络模型,用于生成sql:该模型生成一系列sql,在数据库中执行,以获得奖励,通过奖励来学习生成sql的策略
- 模型利用sql结构来减小生成sql的空间,是的生成问题更简单(Point-network)
- 发布了WikiSQL:有80654个样本,每个样本包含自然语言问题和人工标注的sql
- Seq2SQL的性能执行准确率从35.9%提高到59.4%,逻辑形式准确率从23.4%提高到48.3%
- 奖励公式

模型
- 输入-x的编码器encoder为2层bi-lstm 表格的列名,用于生成select选择哪列,以及condition的左边变量 sql关键词集合, 用于生成sql关键词,如count 自然语言问题,用于生成condition的值
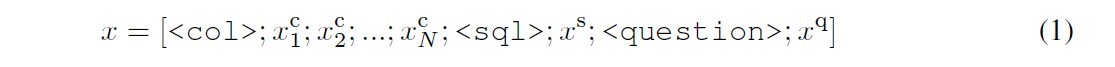
- decoder-采用的pointer network
(1)传统注意力机制公式
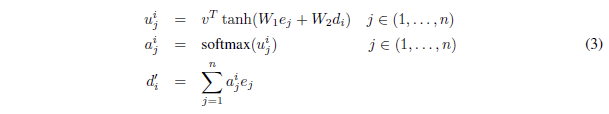 其中是encoder的隐状态,而是decoder的隐状态,v,W1,W2都是可学习的参数,在得到之后对其执行softmax操作即得到。这里的就是分配给输入序列的权重,依据该权重求加权和,然后把得到的拼接(或者加和)到decoder的隐状态上,最后让decoder部分根据拼接后新的隐状态进行解码和预测。
其中是encoder的隐状态,而是decoder的隐状态,v,W1,W2都是可学习的参数,在得到之后对其执行softmax操作即得到。这里的就是分配给输入序列的权重,依据该权重求加权和,然后把得到的拼接(或者加和)到decoder的隐状态上,最后让decoder部分根据拼接后新的隐状态进行解码和预测。
根据传统的注意力机制,作者想到,所谓的正是针对输入序列的权重,完全可以把它拿出来作为指向输入序列的指针,在每次预测一个元素的时候找到输入序列中权重最大的那个元素不就好了嘛!于是作者就按照这个思路对传统注意力机制进行了修改和简化,公式变成了这个样子:
(2)pointer network 公式
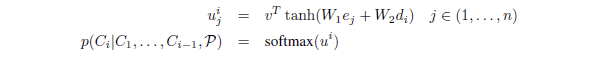 第一个公式和之前没有区别,然后第二个公式则是说Pointer Networks直接将softmax之后得到的当成了输出,让承担指向输入序列特定元素的指针角色。
第一个公式和之前没有区别,然后第二个公式则是说Pointer Networks直接将softmax之后得到的当成了输出,让承担指向输入序列特定元素的指针角色。
所以总结一下,传统的带有注意力机制的seq2seq模型的运行过程是这样的,先使用encoder部分对输入序列进行编码,然后对编码后的向量做attention,最后使用decoder部分对attention后的向量进行解码从而得到预测结果。但是作为Pointer Networks,得到预测结果的方式便是输出一个概率分布,也即所谓的指针。换句话说,传统带有注意力机制的seq2seq模型输出的是针对输出词汇表的一个概率分布,而Pointer Networks输出的则是针对输入文本序列的概率分布。
其实我们可以发现,因为输出元素来自输入元素的特点,Pointer Networks特别适合用来直接复制输入序列中的某些元素给输出序列。
(3)论文
即通过注意力得分直接选取输入序列中最高注意力的token当做sql序列的当前输出

结果
