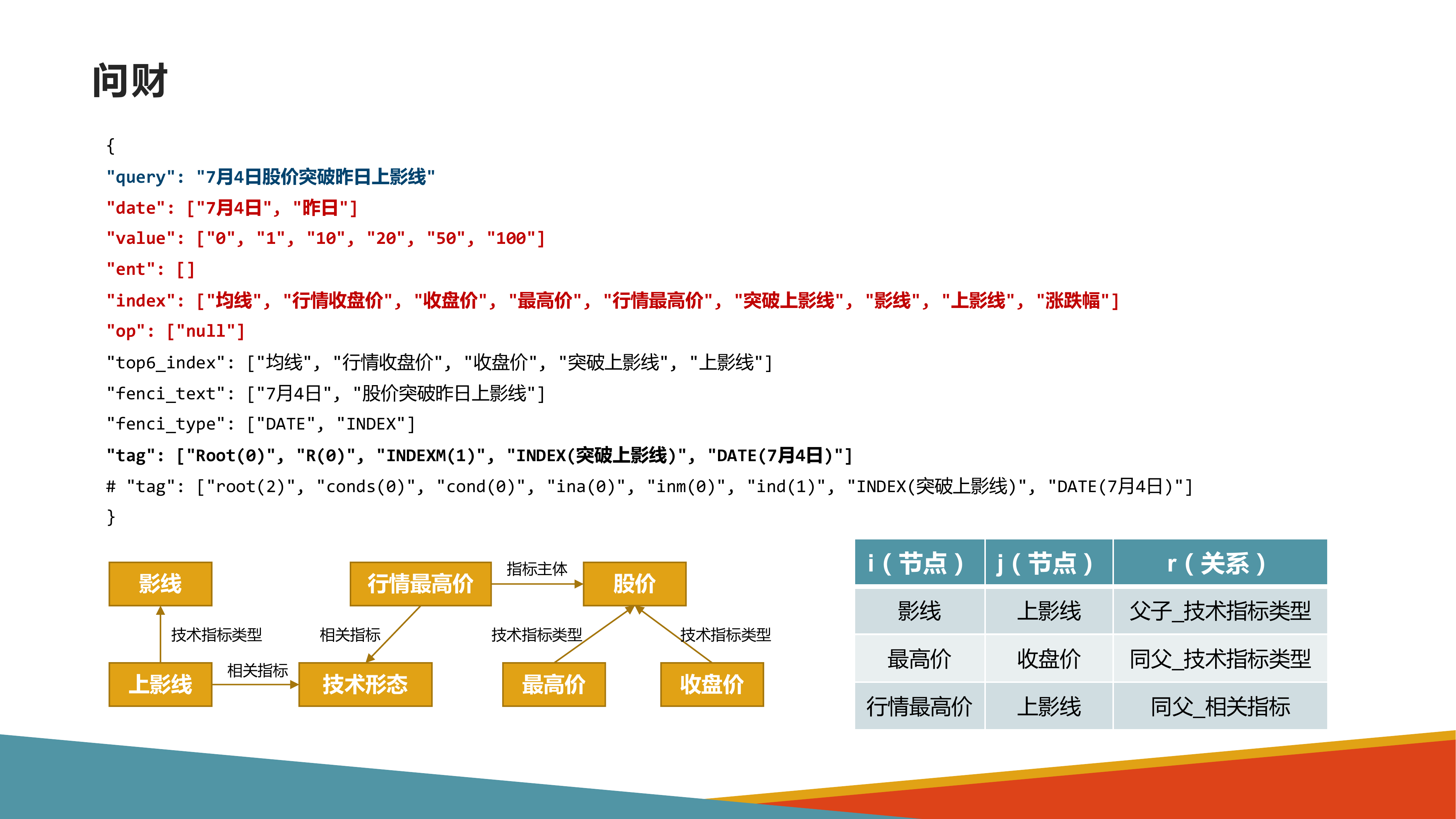
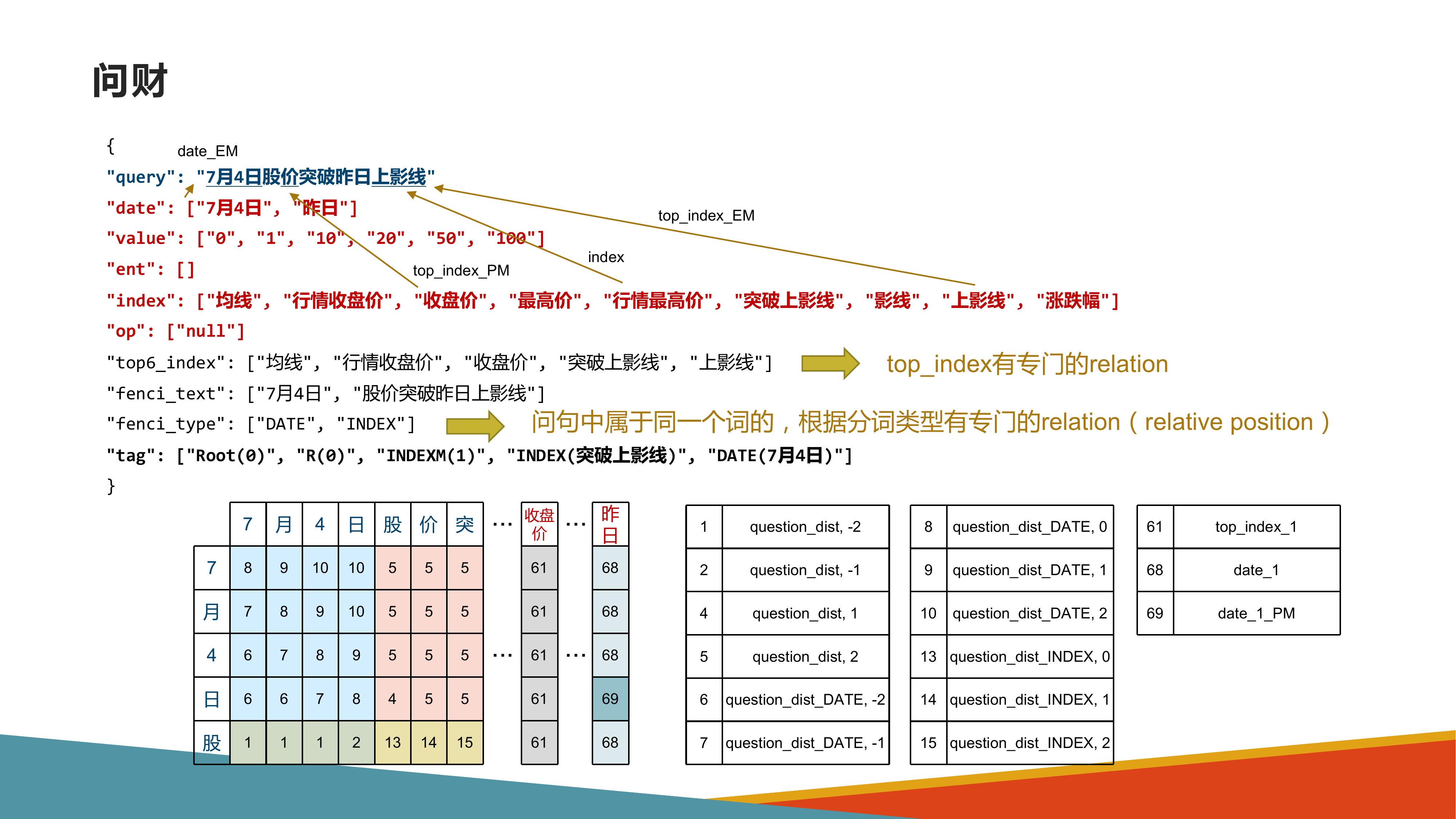
背景
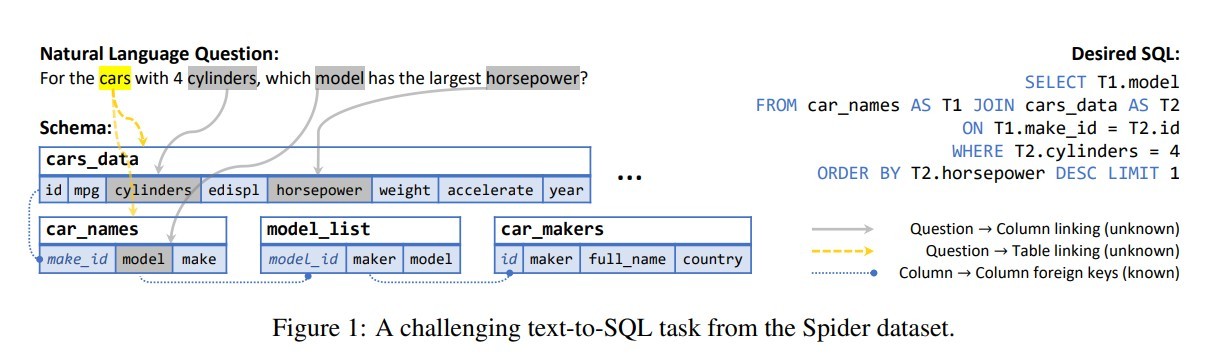
问题中的model在多个表car_name和model_list的字段model、model_id中出现,应该链接到哪一个字段。比如问题中的car在多个表cars_data和car_names出现,应该链接到哪一个表。从而展开研究。
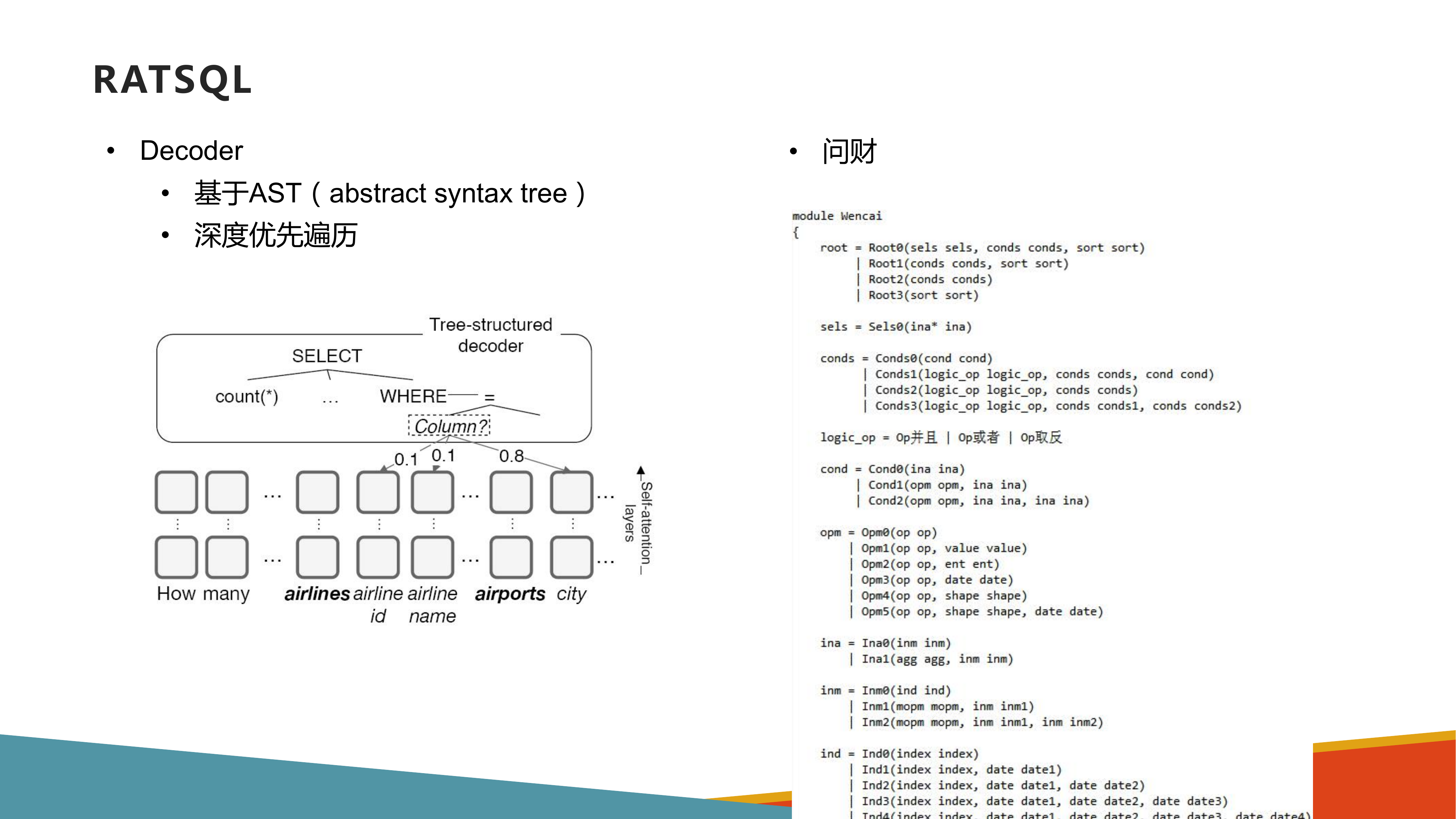
RAT-SQL模型
- Attention is All you Need
Transformer结构是一系列self-attention layers的叠加。考虑$x_i$为输入,self-attention layer的输出为$y_i$。每一层的处理过程如下。其中FC为全连接层,LayerNorm是进行normalization。
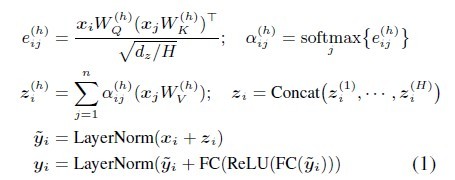
从Transformer架构理解,$e_{ij}$ 为$x_i$的query vector与$x_j$的key vector的点积得分;$α_{ij}$为$x_i$对不同词向量的注意力权重;$z_i$为$x_i$的自注意力输出。普通Transformer结构擅长学习到不同$x_i$之间的关系,但如果$x_i$之间有预先定义好的关联关系,就无法表示出。
- Self-Attention with Relative Position Representations
Shaw et al. (2018)提出了relation-aware self-attention的方法。通过如下方式来在self-attention layer加入输入元素相互间的关系信息。
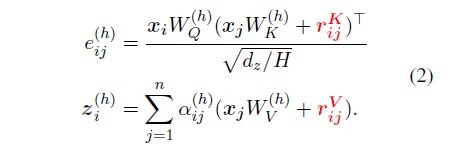
RATSQL基于此进行了进一步的引申,使得该Transformer结构可以表示任意的关系信息。定义 $r^K_{ij}=r^V_{ij}=Concat(ρ^{(1)}{ij},...,ρ^{(R)})$。其中假设有R个关系对,而 $ρ^{(s)}_{ij}$ 为通过学习得到的对关系 $R^{(s)}$ 的向量表示。
Schema
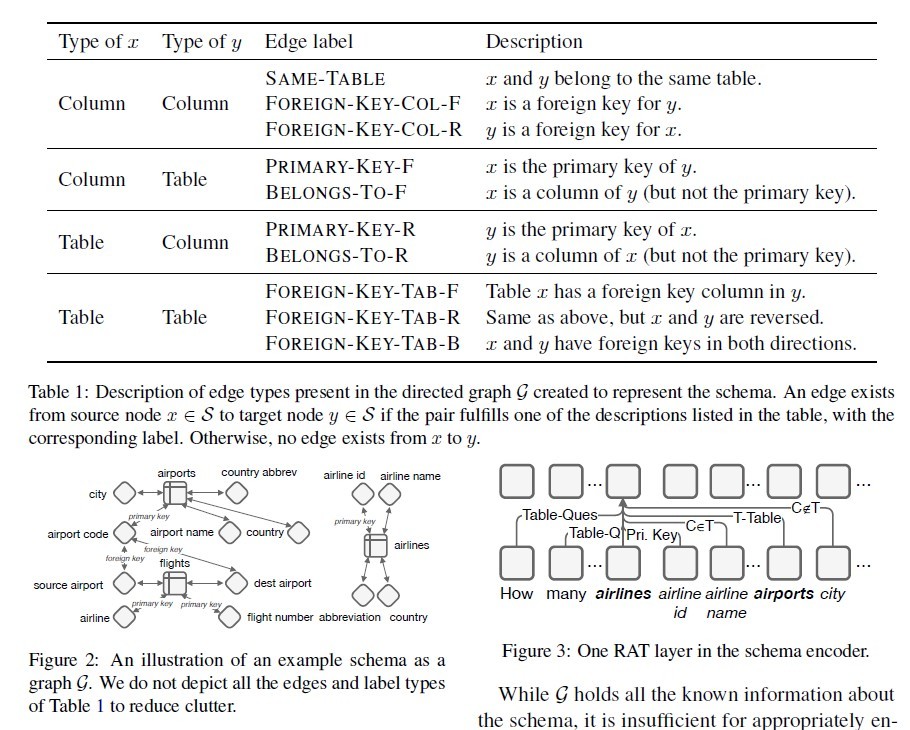
图顶点集合由三部分组成:column names,table names以及question words。对于column,同时在顶点label中加入column type。
图的边集合由三部分组成:首先是Database Schema所定义的表连接关系,table和column的包含关系等等;其次是通过schema linking得到的question和schema之间的对应关系;最后是为辅助relation-aware self-attention而定义的Auxiliary Relations。
- Encoding
首先对Graph中各个节点进行向量化表示,得到初始输入X(如下图)。然后在X之上叠加N个RAT Layers,进行relation-aware self-attention。此时会把各个node之间的关系 同时作为训练输入。
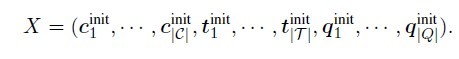
- Decoding
在encoder输出的向量之上通过一系列的预测动作来构造AST(Abstract Syntax Tree):首先,用APPLYRULE来生成基本结构;然后,用SELECTTABLE或者SELECTCOLUMN来完成table name或column name的选择填充。AST生成后,可进一步推断出最终的SQL query。
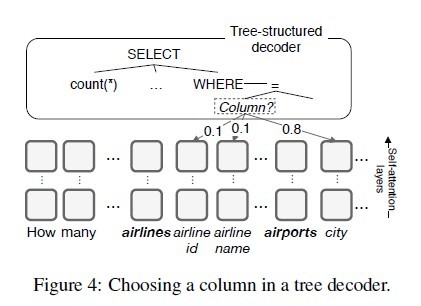
结果
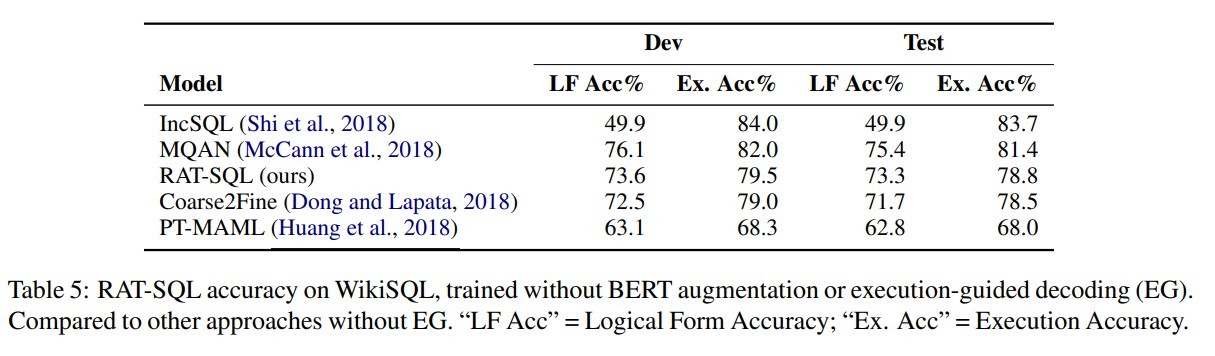

example(来源同事)