论文通过以下方法解决如何提升大型语言模型(LLMs)在Text-to-SQL任务中的推理能力和准确性问题:
1. 提出Reasoning-SQL框架
- 强化学习(RL)框架:论文提出了一个基于强化学习(RL)的框架Reasoning-SQL,通过训练LLMs来增强其推理能力。该框架的核心是利用一组精心设计的奖励函数来指导模型生成更准确的SQL查询。
- 组相对策略优化(GRPO):为了有效整合多种奖励信号,论文采用了组相对策略优化(GRPO)算法。GRPO通过生成每个输入的多个候选SQL查询,并根据这些候选之间的相对表现来计算优势,从而为模型提供更丰富、更有效的反馈。
2. 设计复合奖励函数
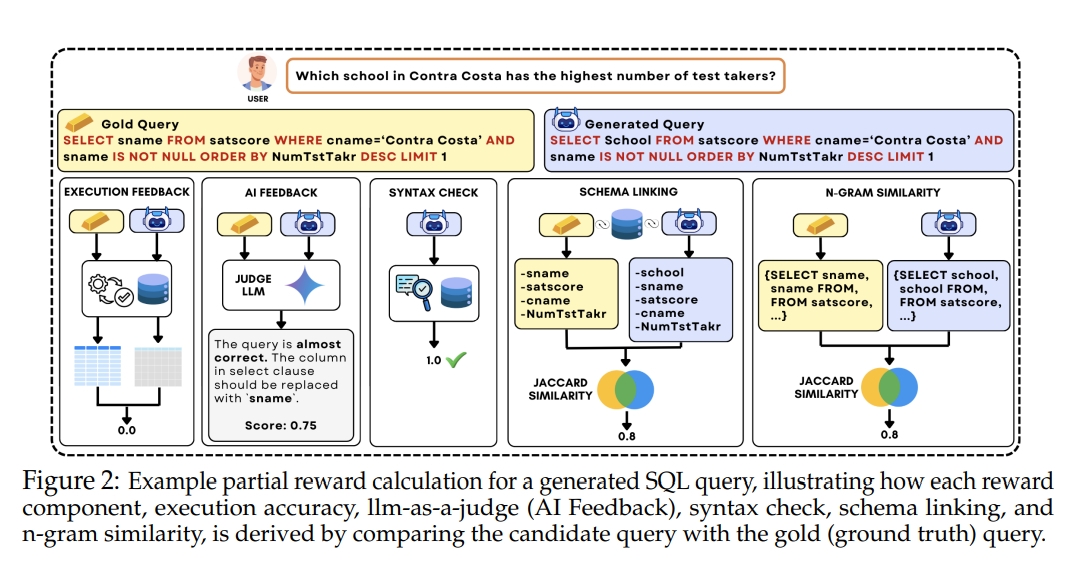
- 执行准确率奖励(RLEF):直接评估生成的SQL查询在数据库上执行后是否产生正确的结果。虽然这是一个直观且重要的奖励信号,但其二元和稀疏的特性在优化过程中存在局限性。
- LLM-as-a-Judge奖励(RLAIF):利用另一个LLM作为评判,对生成的SQL查询进行评估。评判LLM根据一系列设计好的标准(如逻辑一致性、结构相似性和语义正确性)对候选查询进行评分,为模型提供更细致的反馈。
- 语法检查奖励:确保生成的SQL查询在语法上是有效的。即使查询结果不完全正确,只要语法无误,模型也会获得一定的奖励,这有助于模型学习生成更接近正确的查询。
- 模式链接奖励:衡量生成查询中使用的数据库模式元素与正确查询之间的Jaccard相似度。这一奖励直接针对Text-to-SQL任务中模式理解的挑战,帮助模型更准确地将自然语言实体映射到数据库模式中。
- N-gram相似度奖励:计算生成查询与正确查询之间的N-gram相似度。这种奖励利用SQL的结构化特性,通过评估查询的词汇和语法结构的相似度来提供反馈,即使在存在微小差异的情况下也能给予一定的奖励。

3. 实验验证
- 训练目标消融研究:通过对比使用不同奖励函数组合训练的模型,验证了复合奖励函数的有效性。实验结果表明,使用所有提出的奖励函数训练的模型在执行准确率和其他相关指标上均优于仅使用执行准确率奖励的模型。
- 基线比较:将Reasoning-SQL训练的模型与现有的Text-to-SQL方法(包括监督微调(SFT)方法和其他最先进的模型)进行比较。在多个基准数据集上,Reasoning-SQL训练的模型在执行准确率和模式链接方面均取得了更好的结果。
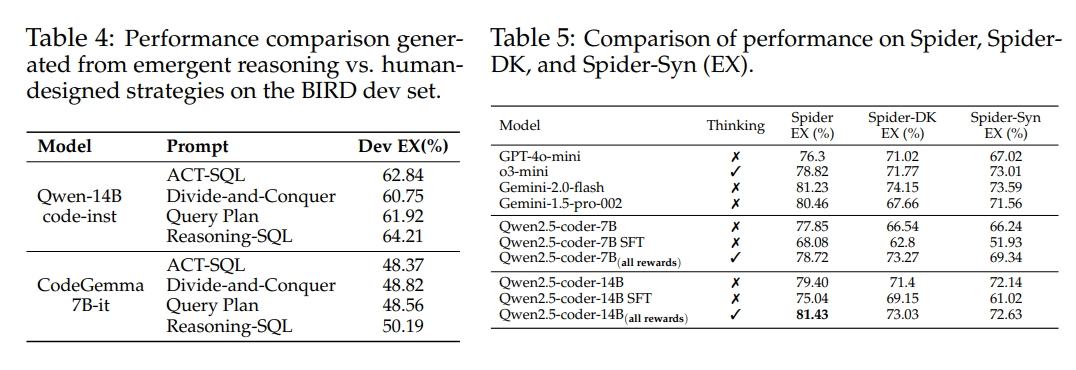
- 推理能力分析:通过观察模型在训练过程中推理风格的变化,发现模型能够自然地发展出更结构化的推理方式,从而生成更准确的SQL查询。此外,通过将模型的推理风格与人类设计的推理策略进行比较,结果表明模型自动生成的推理风格在性能上优于人类设计的策略。
- 泛化能力分析:在Spider、Spider-DK和Spider-Syn等具有不同SQL查询和自然语言问题分布的基准数据集上评估模型的泛化能力。结果表明,Reasoning-SQL训练的模型在这些基准上均优于现有的先进模型,证明了其良好的泛化能力。
4. 实验结果
- 消融实验
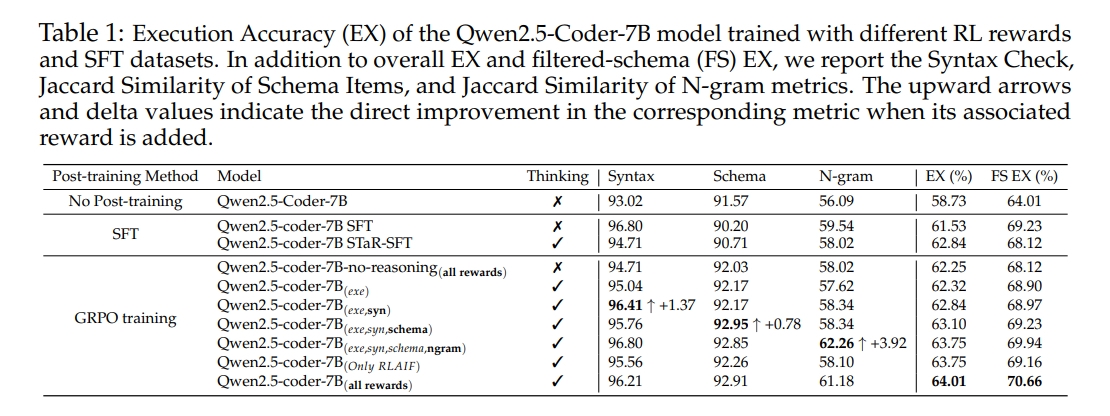
- 不同的模型结果