论文总结来源kimi大模型 papers.cool
Q1: 这篇论文试图解决什么问题?
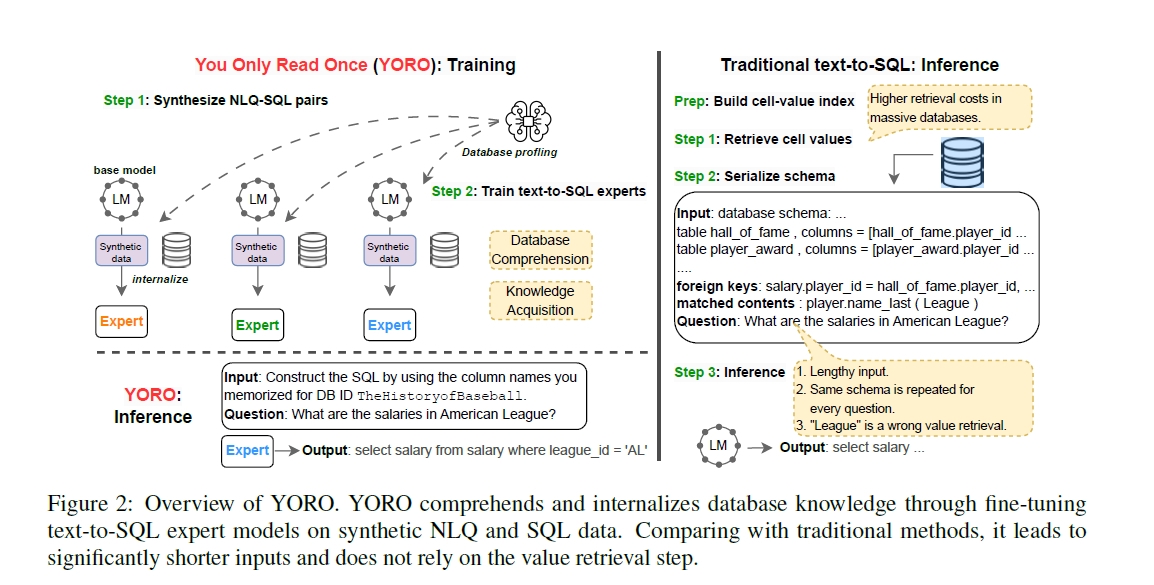
这篇论文提出了一个名为You Only Read Once (YORO)的新范式,旨在解决文本到SQL(text-to-SQL)任务中的几个关键问题:
1.高推理成本:现有的文本到SQL系统在处理每个问题时都需要重复编码相同的数据库模式,这导致了不必要的高计算成本。
2.信息遗漏:线性化的模式输入虽然代表了数据库的高层结构,但可能仍然遗漏了关键信息,如所有可能的单元格值选择、列和单元格值之间的关系以及特定领域的知识。
3.值检索错误和高检索成本:现有系统通常需要对每个问题进行单元格值检索阶段,这个过程增加了额外的检索成本,并且如果检索失败(例如,由于问题中的缩写等情况),可能会导致错误的SQL生成。
为了解决这些问题,YORO在训练期间通过合成文本到SQL数据直接将数据库知识内化为文本到SQL模型的参数知识,并在推理期间消除了对模式编码的需求。这显著减少了输入令牌的长度,同时保持了与传统系统在多个基准测试上的竞争性能,特别是在处理大型数据库和具有挑战性值检索的问题时表现出色。
Q2: 有哪些相关研究?
根据论文内容,与YORO相关的研究领域和工作主要包括:
1.文本到SQL (Text-to-SQL):这是YORO主要解决的问题领域,涉及到将自然语言问题转换为可执行的SQL语句。文中提到了一些使用微调(Fine-tuning)方法来提升文本到SQL性能的研究,以及使用闭源大型语言模型(如GPT-4和Claude)通过提示(Prompting)方法来解决文本到SQL问题的研究。
2.上下文压缩 (Context Compression):这个领域的研究旨在通过压缩和缩短指令或将上下文编码为紧凑表示来提高大型语言模型(LLM)推理的效率。YORO通过知识吸收的方式缩短数据库内容,并将上下文“存储”在模型参数中。
3.合成数据用于文本到SQL (Synthesizing data for Text-to-SQL):为了提升文本到SQL系统的性能,特别是在领域泛化方面,研究者们通过提取SQL骨架和填充占位符来生成多样化的SQL查询,然后使用SQL到文本的生成器(如T5或ChatGPT)来产生自然语言问题和SQL对。
4.特定领域的语义解析 (Single database semantic parsing):YORO可以被看作是文本到SQL中的一个压缩模式设置,这与特定领域的语义解析任务(例如ATIS和GEO)有关联。这些任务通常需要大量的标注示例,而YORO通过合成数据来实现。
5.大型语言模型的继续训练 (Continued training of LLMs):为了进一步提升文本到SQL解析性能,一些研究重新审视了对LLMs进行继续训练的潜力。
6.数据增强 (Data augmentation):通过合成数据来增强文本到SQL系统,尤其是对于新领域数据库的数据合成。
这些相关研究为YORO提供了理论基础和技术背景,同时也展示了文本到SQL任务的多样性和挑战性。YORO通过结合这些领域的技术和方法,提出了一个新颖的解决方案来提高文本到SQL任务的效率和性能。
Q3: 论文如何解决这个问题?
论文提出了一个名为You Only Read Once (YORO)的新范式来解决文本到SQL任务中的高推理成本和信息遗漏问题。YORO通过以下几个关键步骤来解决这些问题:
1.数据库知识获取阶段:在训练期间,YORO首先对目标数据库的内容进行全面理解,并将数据库信息直接内化为文本到SQL模型的参数知识。这是通过在目标数据库上生成合成的文本到SQL数据,并在这些数据上继续训练语言模型来实现的。
2.训练文本到SQL专家模型:YORO为每个特定的目标数据库训练一个专家模型。这种设计考虑了数据库模式的动态性和模糊性,以及同一列名在不同数据库中可能具有不同含义的情况。通过训练专家模型,YORO可以减少跨数据库知识冲突,并提高整体性能。
3.推理阶段:在推理时,YORO不再需要对数据库模式进行编码,可以直接将自然语言问题转换为基于数据库的SQL查询。这种方法与传统方法相比,大大简化了处理过程,减少了潜在的错误和成本。
4.简化输入:YORO通过内化数据库知识,显著减少了输入令牌的长度,平均减少了66%-98%。这不仅提高了计算效率,而且对于大型数据库尤其有益,因为输入长度不再随数据库大小变化。
5.处理具有挑战性的值检索:YORO在知识获取阶段通过合成数据学习数据库值,这使得它能够在推理期间消除单独的值检索步骤,并学习处理具有挑战性的单元格值,如问题中的缩写。
6.实验验证:通过在Spider、KaggleDBQA和BIRD等流行的文本到SQL基准测试上的广泛评估,论文证明了YORO与传统方法相比在不同模型选择上具有竞争力的表现,并且在处理大型数据库和具有挑战性值检索的问题时表现尤为出色。
通过这些方法,YORO旨在提高文本到SQL任务的效率和准确性,同时减少对数据库内容的直接依赖,降低推理成本。
Q4: 论文做了哪些实验?
论文中进行了一系列实验来评估YORO模型的性能,这些实验包括:
1.实验设置:使用了三个广泛使用的文本到SQL数据集进行评估,分别是Spider、KaggleDBQA和BIRD。这些数据集具有不同的特点,例如Spider数据集的表和列名比较简单明确,而KaggleDBQA和BIRD使用更接近真实情况的数据库,包含缩写和模糊的列名。
2.评估指标:主要使用执行准确率(execution accuracies)来衡量文本到SQL任务的结果,并提供了所有数据库的微观(micro)和宏观(macro)平均结果。
3.实现细节:使用Anthropic的Claude-3Sonnet模型生成合成数据。对于SQL骨架提取和NLQ生成,设置了特定的温度参数以控制生成的多样性。
4.结果和讨论:将YORO模型与CodeS和PICARD这两种输入格式的基线模型进行了比较。结果显示,YORO在不同数据集上的表现与这些传统方法相当,甚至在某些情况下表现更好。
5.不同合成数据规模的实验:研究了不同规模的合成数据对YORO性能的影响。结果表明,即使是少量的合成数据也能显著提高性能。
6.标准微调与LoRA微调的比较:探讨了使用LoRA(Low-Rank Adaptation)技术进行参数有效微调的效果,并与标准微调进行了比较。
7.不同模型大小的实验:研究了使用不同大小的LLaMA模型对YORO性能的影响。
8.消融研究:通过逐一移除YORO模型的不同组件并重新训练,评估了每个组件对整体性能的贡献。
9.案例研究:进一步探讨了YORO在处理大型数据库和具有挑战性的值检索问题时的优势。
10.错误分析:对YORO模型在实验中出现的错误进行了详细分析。
这些实验全面评估了YORO模型在文本到SQL任务中的性能,并与现有技术进行了比较,证明了其有效性和潜在优势。
Q5: 有什么可以进一步探索的点?
论文中提到了几个可以进一步探索的点:
1.合成数据的质量和数量:研究如何生成更高质量的合成数据以及合成数据的最优数量,以便更有效地训练模型。
2.LoRA微调:进一步探索使用LoRA(Low-Rank Adaptation)进行参数有效微调的效果,以及它在不同规模的模型上的表现。
3.不同模型大小的影响:研究不同大小的语言模型对YORO性能的影响,以及是否存在一个最佳的模型大小。
4.跨数据库知识冲突:深入研究如何更有效地缓解跨数据库知识冲突,以及如何进一步提升专家模型在特定数据库上的性能。
5.处理大型数据库:探索YORO在处理具有大量列和表的大型数据库时的性能,以及如何进一步优化以提高效率和准确性。
6.具有挑战性的值检索:研究YORO在处理具有挑战性的值检索问题(如缩写和复杂指示词)时的表现,并探索如何进一步提升其在这些情况下的性能。
7.错误分析和模型改进:进行更深入的错误分析,以识别YORO模型的常见错误类型,并探索如何改进模型以减少这些错误。
8.实际应用和部署:研究如何将YORO模型部署到实际应用中,以及在实际环境中可能遇到的挑战和限制。
9.与其他NLP任务的结合:探索将YORO与其他自然语言处理任务(如问答系统、信息检索等)结合的可能性,以及如何利用YORO来提升这些任务的性能。
10.用户交互和反馈:研究如何将用户交互和反馈整合到YORO模型中,以便模型能够根据用户的输入和需求进行自我调整和优化。
这些探索点可以帮助研究者更深入地理解YORO模型的潜力,以及如何进一步改进和优化该模型以应对各种挑战。
Q6: 总结一下论文的主要内容
这篇论文提出了一个名为You Only Read Once (YORO)的新范式,用以改进文本到SQL(Text-to-SQL)任务的性能和效率。主要内容可以总结如下:
1.问题陈述:传统的Text-to-SQL系统在处理问题时需要重复编码数据库模式,导致计算效率低下和可能遗漏关键信息。此外,这些系统在处理具有挑战性的值检索问题时,如问题中的缩写,表现不佳。
2.YORO范式:YORO通过在训练阶段内化数据库知识到模型参数中,消除了在推理阶段对数据库模式编码的需求。这使得YORO能够处理更短的输入,同时提高了推理效率。
3.知识获取:YORO通过合成大量的自然语言问题和SQL查询对,让模型在训练时全面理解数据库内容,并将这些信息吸收到模型权重中。
4.专家模型:YORO训练针对特定数据库的专家模型,以适应数据库之间的差异和复杂性,从而提高整体性能。
5.实验评估:通过在Spider、KaggleDBQA和BIRD等标准数据集上的实验,论文证明了YORO与传统方法相比,在保持竞争力的同时显著减少了输入长度。
6.优势:YORO在处理大型数据库和具有挑战性值检索的问题时表现出色,因为它不需要在推理时进行耗时的值检索步骤。
7.贡献:论文的贡献包括提出了YORO这一新的Text-to-SQL范式,证明了其在多个基准测试中的有效性,并通过案例研究展示了其在特定情况下的优势。
8.未来工作:论文指出了未来研究的方向,包括进一步优化合成数据生成,探索更有效的微调方法,以及将YORO应用于实际场景中的挑战。
总的来说,YORO通过在训练阶段内化数据库知识,并在推理阶段无需访问数据库,提供了一种高效的Text-to-SQL解决方案,能够在减少计算成本的同时保持或提高性能。