1. 背景:为什么需要位置编码?
原始的 Transformer 模型本身是 置换不变 的。也就是说,它对输入序列中单词的顺序不敏感。如果不提供位置信息,模型会将句子 “猫追老鼠” 和 “老鼠追猫” 视为相同的。
为了解决这个问题,我们需要一种方法将单词的顺序或位置信息注入到模型中。经典的 Transformer 使用了 正弦余弦位置编码,将其与词向量相加。后来,像 T5 这样的模型则使用了相对位置编码,在注意力机制中通过偏置项来体现词与词之间的相对距离。
2. ALiBi 的核心思想
ALiBi 的全称是 Attention with Linear Biases(带线性偏置的注意力)。
它的核心思想非常简单且直观:
“惩罚”注意力分数,惩罚量与两个词之间的距离成线性关系。离得越远的词,受到的惩罚越大。
它不在输入层面添加任何位置向量,而是直接修改注意力机制的计算过程。
3. ALiBi 的工作原理
我们来看一下它是如何实现的。
1. 标准注意力分数计算: 在标准的自注意力中,查询向量(Query)和键向量(Key)之间的分数计算为: $$ \text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d_k}} \right) V $$ 其中 $$ S = \frac{QK^T}{\sqrt{d_k}} $$ 被称为注意力分数矩阵。
2. ALiBi 的修改: ALiBi 在这个分数矩阵 ( S ) 上直接加上一个静态的、非学习的偏置矩阵 ( M )。 $$ \text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d_k}} + M \right) V $$
3. 偏置矩阵 ( M ) 是如何构造的?
- ( M ) 不是一个通过训练学习到的参数。
- 它是一个预先定义好的矩阵,其值只与两个 token 之间的相对距离有关。
- 假设我们有一个长度为 4 的序列
[A, B, C, D]。 - 在计算 token
A对所有 token 的注意力时,我们需要为A与A,A与B,A与C,A与D的注意力分数分别加上一个偏置。 -
这个偏置是基于
A与其他 token 的相对位置来确定的。A到A的距离是 0,偏置 = 0A到B的距离是 1,偏置 =-mA到C的距离是 2,偏置 =-2mA到D的距离是 3,偏置 =-3m
-
这里的
m是一个与注意力头相关的斜率。对于有 ( n ) 个头的模型,每个头 ( i ) 的 ( m ) 值定义为: $ m_i = \frac{1}{2^{8i/n}} $ 例如,一个 8 头的模型,其头的斜率分别是:$ \frac{1}{2^1}, \frac{1}{2^2}, ..., \frac{1}{2^8} $。 - 最终,矩阵 ( M ) 看起来像一个“斜坡”,左上角为 0,向右下角方向线性递减(为负值)。
一个简化的 ( M ) 矩阵示例(对于4个token的序列,假设 m=1):
M =
[ 0 -∞ -∞ -∞ ]
[ -1 0 -∞ -∞ ]
[ -2 -1 0 -∞ ]
[ -3 -2 -1 0 ]
(在实际应用中,-inf 的部分是用于掩盖未来信息的因果掩码,ALiBi 的偏置是加在非 -inf 的位置上。)
4. ALiBi 的优势
- 强大的外推能力
- 这是 ALiBi 最突出的优点。在训练时使用较短的序列(如 1024 个 token),模型无需任何微调就能在推理时处理长得多的序列(如 16K+ 个 token)。
-
因为它的偏置是线性的。模型在训练时学会了“距离越远,注意力越少”的线性关系。当序列变长时,这个线性规则可以自然地推广到更远的距离。而正弦编码等绝对位置编码在遇到训练时未见过的位置时,性能会急剧下降。
-
无需位置嵌入参数
-
ALiBi 不向模型中添加任何可学习的参数(偏置矩阵 ( M ) 是静态计算的)。这使得模型更小,训练更稳定。
-
训练速度更快
-
由于不需要计算位置向量的内积,并且在推理时可以缓存 ( M ) 矩阵,ALiBi 通常能带来轻微的训练和推理速度提升。
-
在多种任务上表现优异
- 论文中的实验表明,ALiBi 在语言建模、机器翻译等任务上,性能不逊于甚至优于其他位置编码方法,同时具备了无与伦比的外推能力。
5. 总结与比喻
你可以把 ALiBi 想象成一个内置的、基于距离的注意力衰减机制。
- 标准注意力:模型需要自己去学习“距离近的词可能更相关”这个模式。
- ALiBi:我们直接“告诉”模型这个模式——“对于每个查询,你更应该关注它附近的词,并且关注度随着距离线性下降”。我们通过一个固定的、线性的惩罚项来强制模型遵循这个模式。
这种直接的“硬编码”先验知识,反而让模型具备了强大的泛化能力,尤其是在处理长序列时。正因为如此,ALiBi 被广泛应用于需要超长上下文的大型语言模型中,例如 MosaicML 的 MPT 系列模型 就采用了 ALiBi。
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
import matplotlib.pyplot as plt
class ALiBiPositionalBias(nn.Module):
"""
ALiBi (Attention with Linear Biases) 位置编码实现
"""
def __init__(self, num_heads, max_positions=512):
super().__init__()
self.num_heads = num_heads
self.max_positions = max_positions
# 为每个头生成斜率 (slope)
slopes = torch.Tensor(self._get_slopes(num_heads))
self.register_buffer('slopes', slopes)
# 预计算偏置矩阵
self.register_buffer('bias_matrix', self._precompute_bias_matrix())
def _get_slopes(self, n):
"""
为 n 个头生成斜率,按照论文中的公式
"""
def get_slopes_power_of_2(n):
start = (2**(-2**-(math.log2(n)-3)))
ratio = start
return [start*ratio**i for i in range(n)]
if math.log2(n).is_integer():
return get_slopes_power_of_2(n)
else:
# 最接近的2的幂
closest_power_of_2 = 2 ** math.floor(math.log2(n))
return (get_slopes_power_of_2(closest_power_of_2) +
self._get_slopes(2 * closest_power_of_2)[0::2][:n - closest_power_of_2])
def _precompute_bias_matrix(self):
"""
预计算偏置矩阵
"""
# 创建相对位置矩阵
context_position = torch.arange(self.max_positions).unsqueeze(0) # [1, seq_len]
memory_position = torch.arange(self.max_positions).unsqueeze(1) # [seq_len, 1]
# 相对位置 = 目标位置 - 源位置
relative_position = memory_position - context_position # [seq_len, seq_len]
relative_position = torch.abs(relative_position)
# 为每个头创建偏置矩阵 [num_heads, seq_len, seq_len]
bias_matrix = torch.zeros(self.num_heads, self.max_positions, self.max_positions)
for h in range(self.num_heads):
# 每个头使用自己的斜率
bias_matrix[h] = -relative_position * self.slopes[h]
return bias_matrix
def forward(self, seq_len):
"""
返回对应序列长度的偏置矩阵
Args:
seq_len: 序列长度
Returns:
bias: [num_heads, seq_len, seq_len] 的偏置矩阵
"""
if seq_len <= self.max_positions:
return self.bias_matrix[:, :seq_len, :seq_len]
else:
# 如果序列长度超过预计算的最大长度,动态计算
context_position = torch.arange(seq_len).unsqueeze(0)
memory_position = torch.arange(seq_len).unsqueeze(1)
relative_position = memory_position - context_position
relative_position = torch.abs(relative_position)
bias_matrix = torch.zeros(self.num_heads, seq_len, seq_len)
for h in range(self.num_heads):
bias_matrix[h] = -relative_position * self.slopes[h]
return bias_matrix.to(self.bias_matrix.device)
class ALiBiAttention(nn.Module):
"""
集成 ALiBi 的自注意力层
"""
def __init__(self, d_model, num_heads, max_positions=512):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.head_dim = d_model // num_heads
assert d_model % num_heads == 0, "d_model 必须能被 num_heads 整除"
# 线性变换层
self.wq = nn.Linear(d_model, d_model)
self.wk = nn.Linear(d_model, d_model)
self.wv = nn.Linear(d_model, d_model)
self.wo = nn.Linear(d_model, d_model)
# ALiBi 偏置
self.alibi = ALiBiPositionalBias(num_heads, max_positions)
def forward(self, x, mask=None):
"""
Args:
x: [batch_size, seq_len, d_model]
mask: 可选的注意力掩码 [batch_size, seq_len, seq_len]
Returns:
output: [batch_size, seq_len, d_model]
"""
batch_size, seq_len, d_model = x.shape
# 线性变换
Q = self.wq(x) # [batch_size, seq_len, d_model]
K = self.wk(x) # [batch_size, seq_len, d_model]
V = self.wv(x) # [batch_size, seq_len, d_model]
# 重塑为多头
Q = Q.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
K = K.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
V = V.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
# 计算注意力分数
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.head_dim)
# scores: [batch_size, num_heads, seq_len, seq_len]
# 添加 ALiBi 偏置
alibi_bias = self.alibi(seq_len) # [num_heads, seq_len, seq_len]
scores = scores + alibi_bias.unsqueeze(0) # 添加batch维度
# 应用可选的注意力掩码
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 计算注意力权重
attention_weights = F.softmax(scores, dim=-1)
# 应用注意力权重到值向量
output = torch.matmul(attention_weights, V) # [batch_size, num_heads, seq_len, head_dim]
# 重塑回原始形状
output = output.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)
# 最终线性变换
output = self.wo(output)
return output, attention_weights
def demo_alibi_attention():
"""演示 ALiBi 注意力的使用"""
print("=== ALiBi 位置编码 Demo ===\n")
# 设置参数
d_model = 64
num_heads = 4
batch_size = 2
seq_len = 8
# 创建模型和随机输入
attention_layer = ALiBiAttention(d_model, num_heads)
x = torch.randn(batch_size, seq_len, d_model)
print(f"输入形状: {x.shape}")
print(f"模型参数: d_model={d_model}, num_heads={num_heads}")
# 前向传播
output, attn_weights = attention_layer(x)
print(f"输出形状: {output.shape}")
print(f"注意力权重形状: {attn_weights.shape}")
return attention_layer, x, output, attn_weights
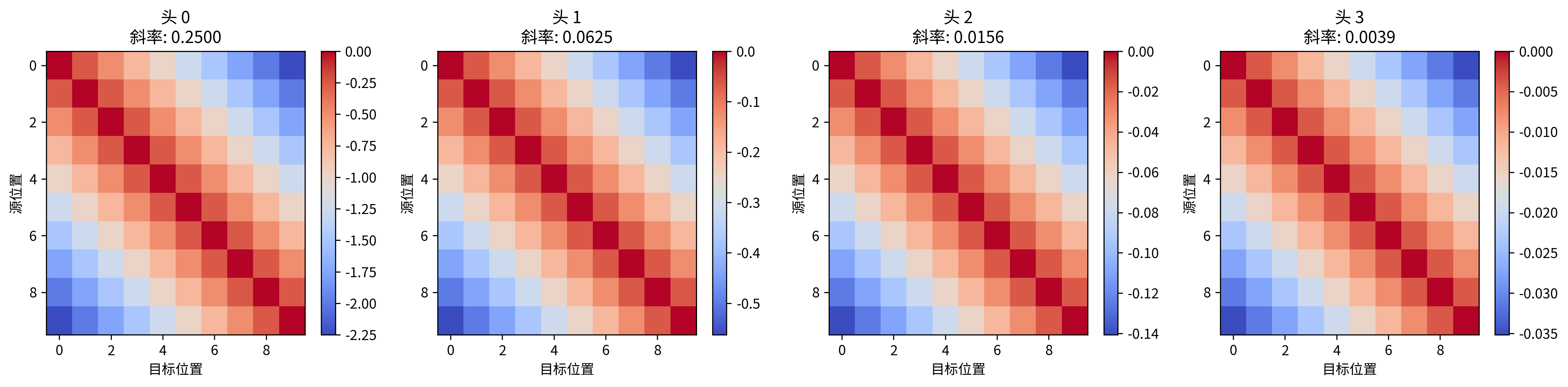
def visualize_alibi_bias():
"""可视化 ALiBi 偏置矩阵"""
print("\n=== 可视化 ALiBi 偏置矩阵 ===")
num_heads = 4
seq_len = 10
alibi = ALiBiPositionalBias(num_heads)
# 获取偏置矩阵
bias_matrix = alibi(seq_len)
# 打印斜率
print(f"各头的斜率: {alibi.slopes.tolist()}")
# 可视化每个头的偏置矩阵
fig, axes = plt.subplots(1, num_heads, figsize=(16, 4))
for i in range(num_heads):
im = axes[i].imshow(bias_matrix[i].detach().numpy(), cmap='coolwarm', aspect='auto')
axes[i].set_title(f'头 {i}\n斜率: {alibi.slopes[i]:.4f}')
axes[i].set_xlabel('目标位置')
axes[i].set_ylabel('源位置')
plt.colorbar(im, ax=axes[i])
plt.tight_layout()
plt.savefig('alibi_bias_matrix.png', dpi=300, bbox_inches='tight')
print("偏置矩阵可视化已保存为 'alibi_bias_matrix.png'")
return bias_matrix
def test_extrapolation():
"""测试 ALiBi 的外推能力"""
print("\n=== 测试外推能力 ===")
# 训练时的序列长度
train_seq_len = 8
# 推理时的序列长度(比训练时长)
eval_seq_len = 16
num_heads = 4
alibi = ALiBiPositionalBias(num_heads, max_positions=eval_seq_len)
# 获取训练和推理时的偏置矩阵
train_bias = alibi(train_seq_len)
eval_bias = alibi(eval_seq_len)
print(f"训练序列长度: {train_seq_len}")
print(f"推理序列长度: {eval_seq_len}")
print(f"偏置矩阵可以无缝扩展到更长的序列")
# 检查训练部分的偏置是否一致
train_part_from_eval = eval_bias[:, :train_seq_len, :train_seq_len]
is_consistent = torch.allclose(train_bias, train_part_from_eval, atol=1e-6)
print(f"训练部分在扩展后保持一致: {is_consistent}")
return train_bias, eval_bias
if __name__ == "__main__":
# 设置随机种子以便复现
torch.manual_seed(42)
# 运行演示
attention_layer, x, output, attn_weights = demo_alibi_attention()
# 可视化偏置矩阵
bias_matrix = visualize_alibi_bias()
# 测试外推能力
train_bias, eval_bias = test_extrapolation()
print("\n=== Demo 完成 ===")
print("这个 Demo 展示了:")
print("1. ALiBi 位置编码的实现")
print("2. 如何集成到自注意力机制中")
print("3. 偏置矩阵的可视化")
print("4. ALiBi 强大的外推能力")